Heteroscedastic Linear Mixed Models with glmmTMB and nlme::lme
Author
Lukas Graz
Published
December 4, 2024
Summary:
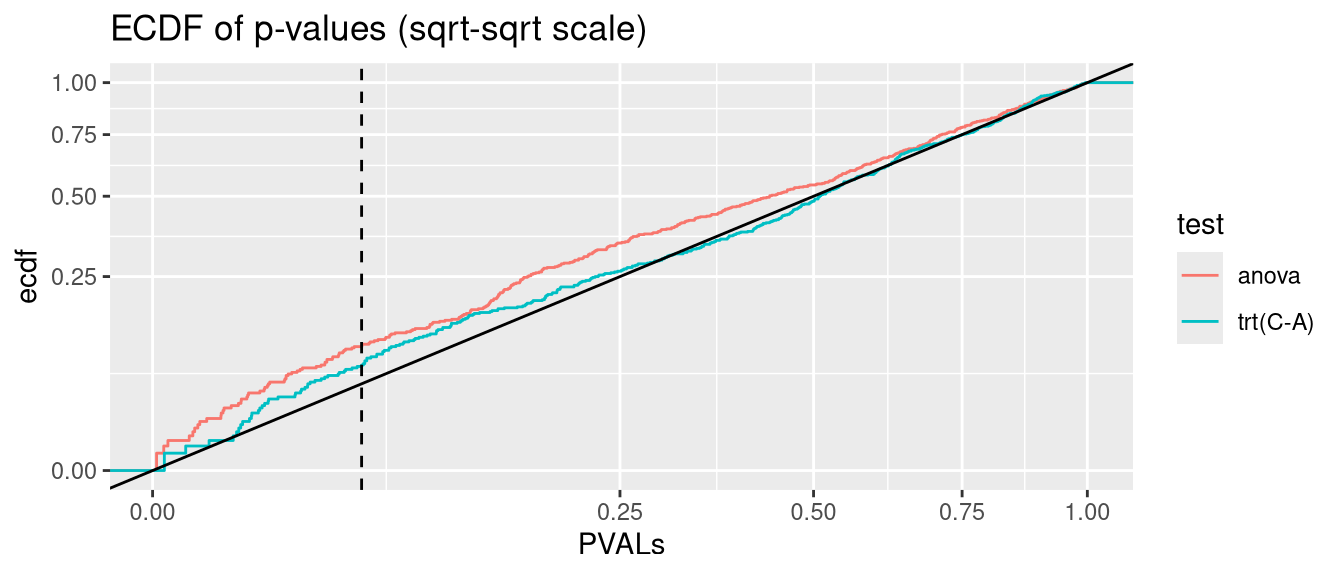
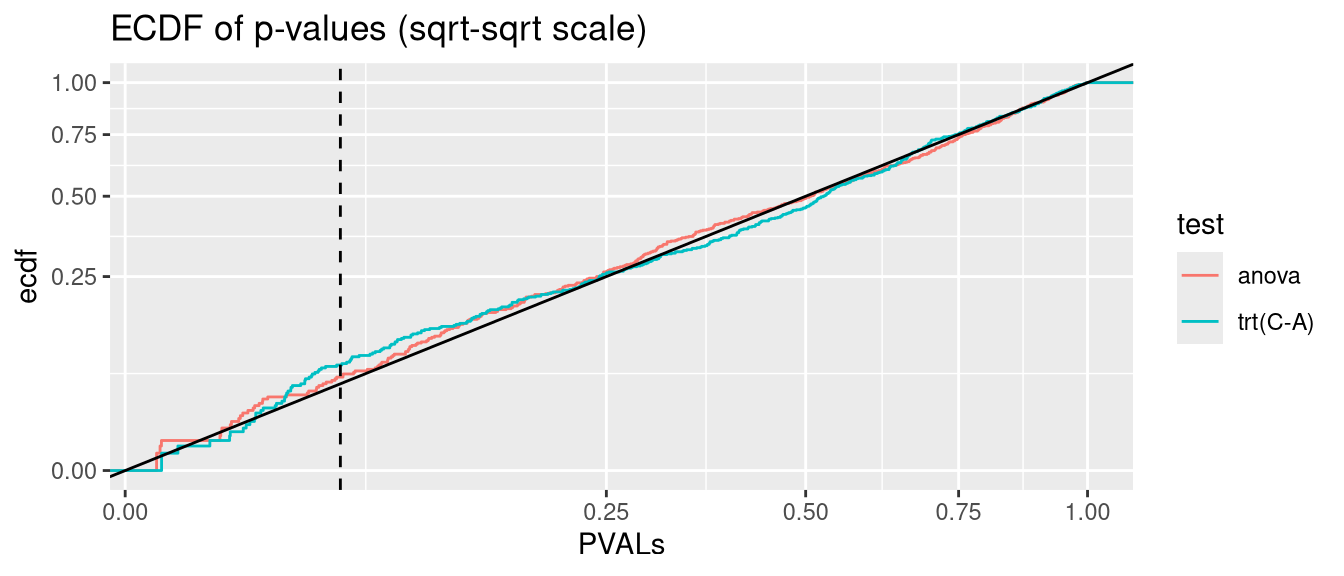
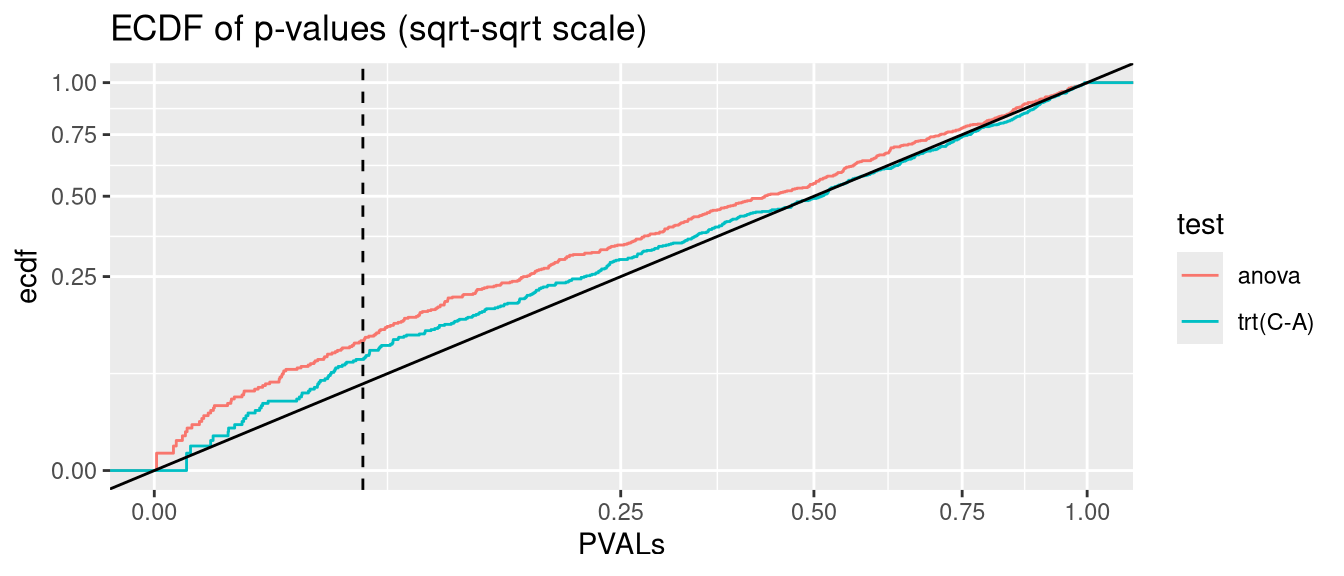
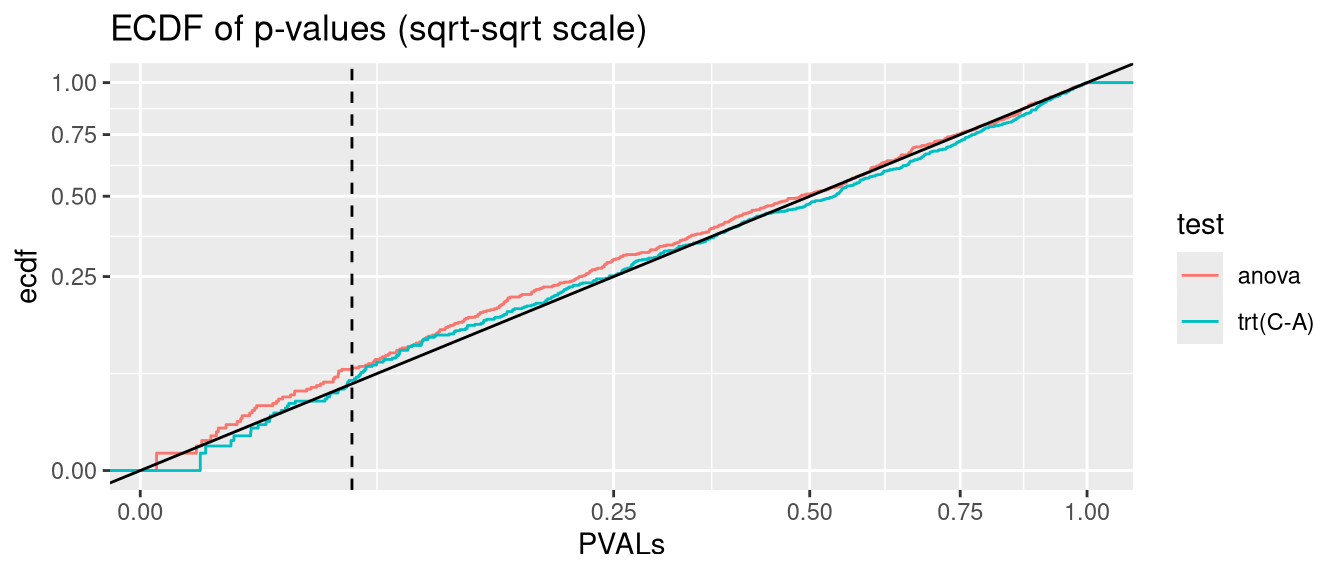
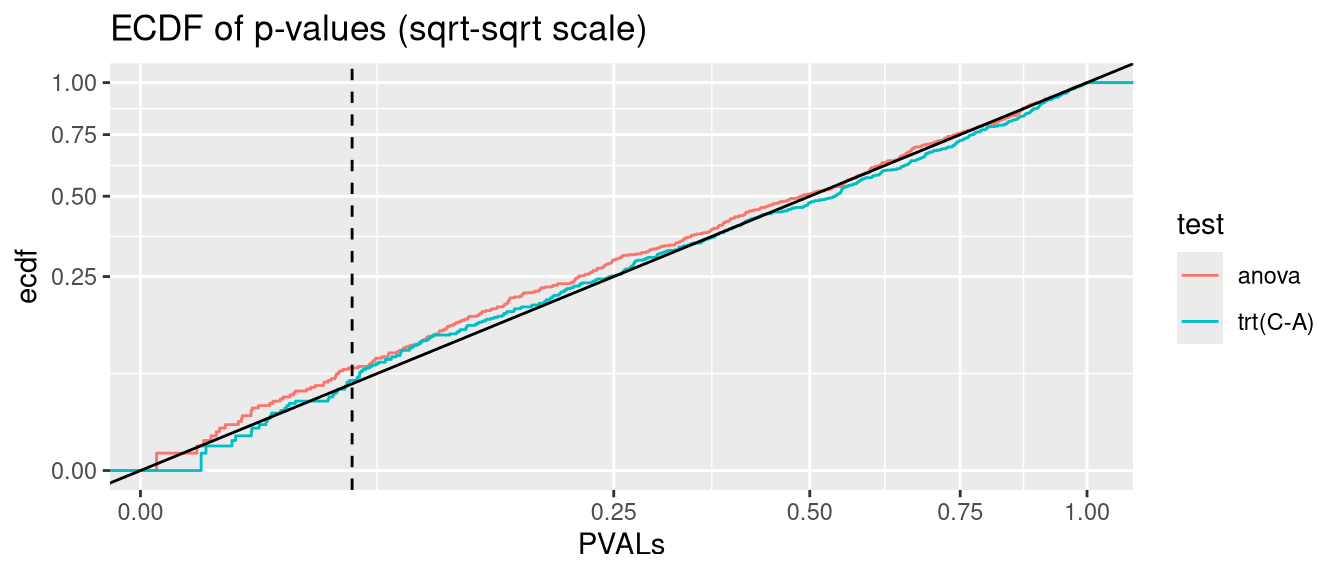
glmmTMB can model heteroscedastic data via the dispformula argument (c.f. section Section 2.3). But Type I error rate is significantly inflated. P-values are not valid
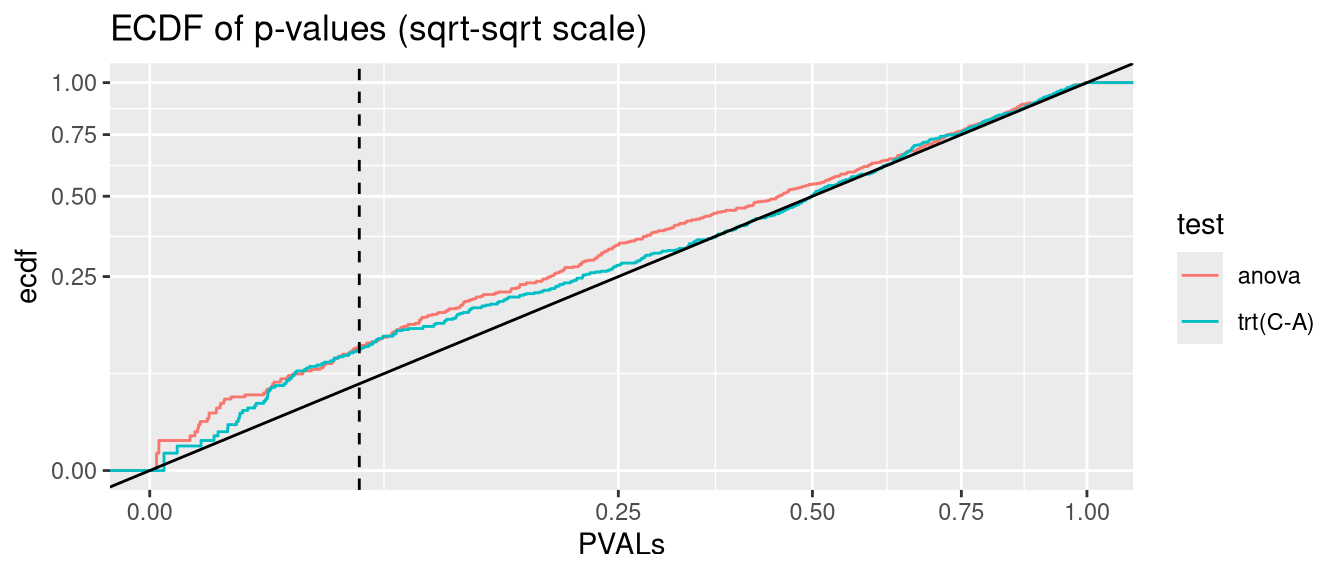
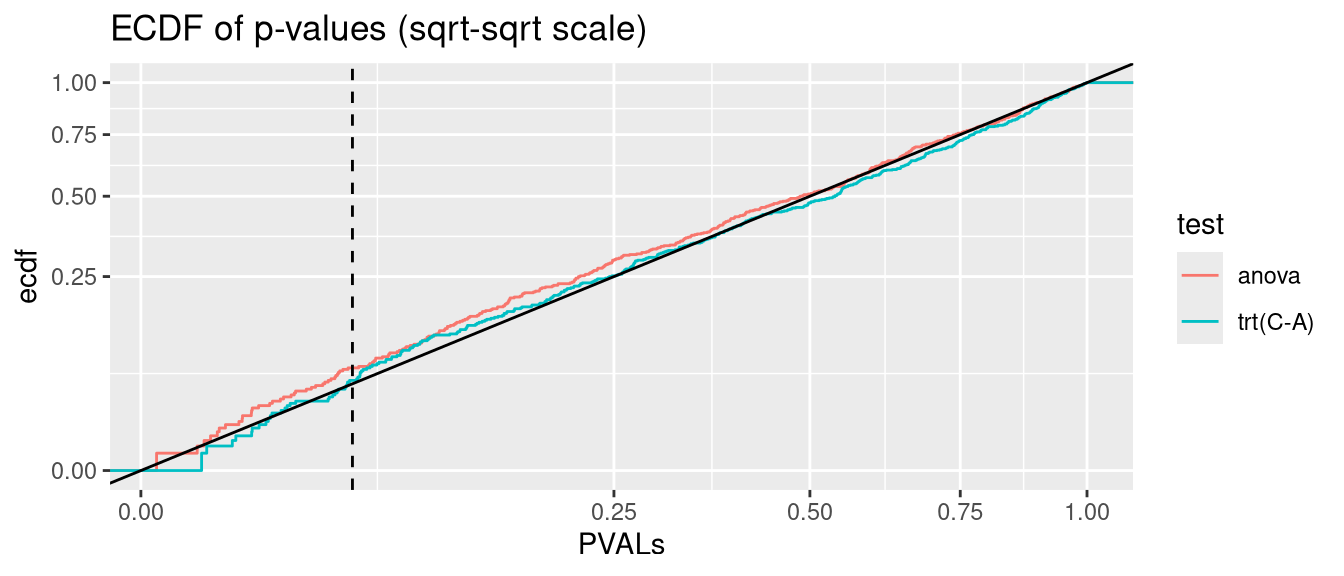
nlme::lme models give valid p-values when accounting for heteroscedasticity with weights=varIdent(form=). They cannot handly corssed random effects afaik.
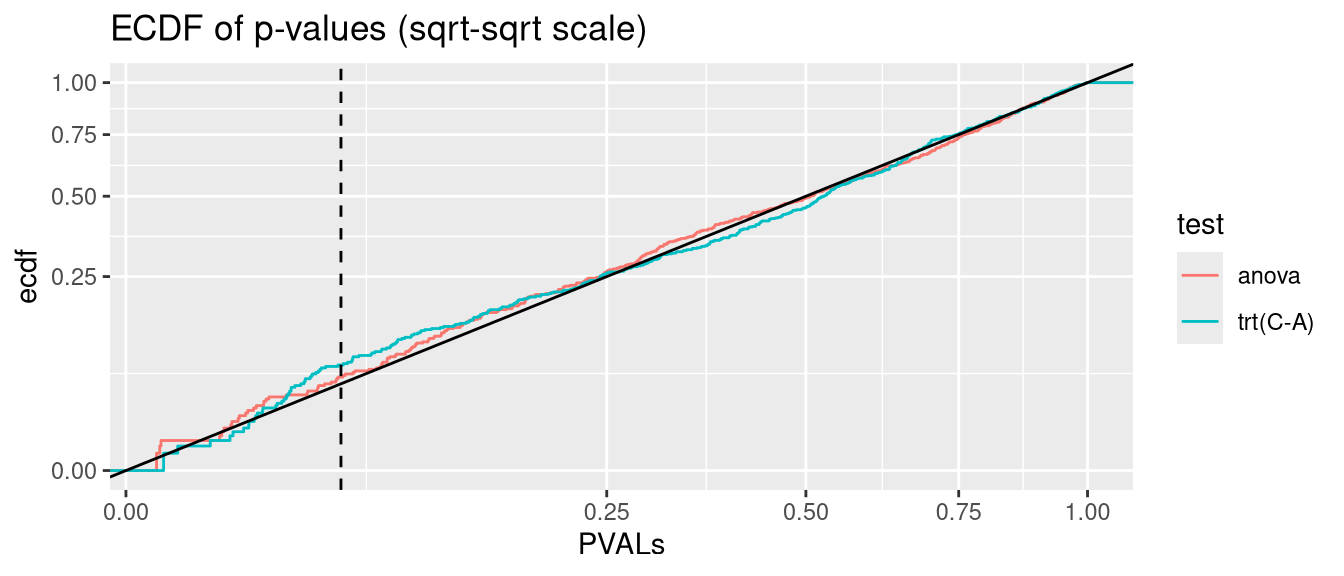
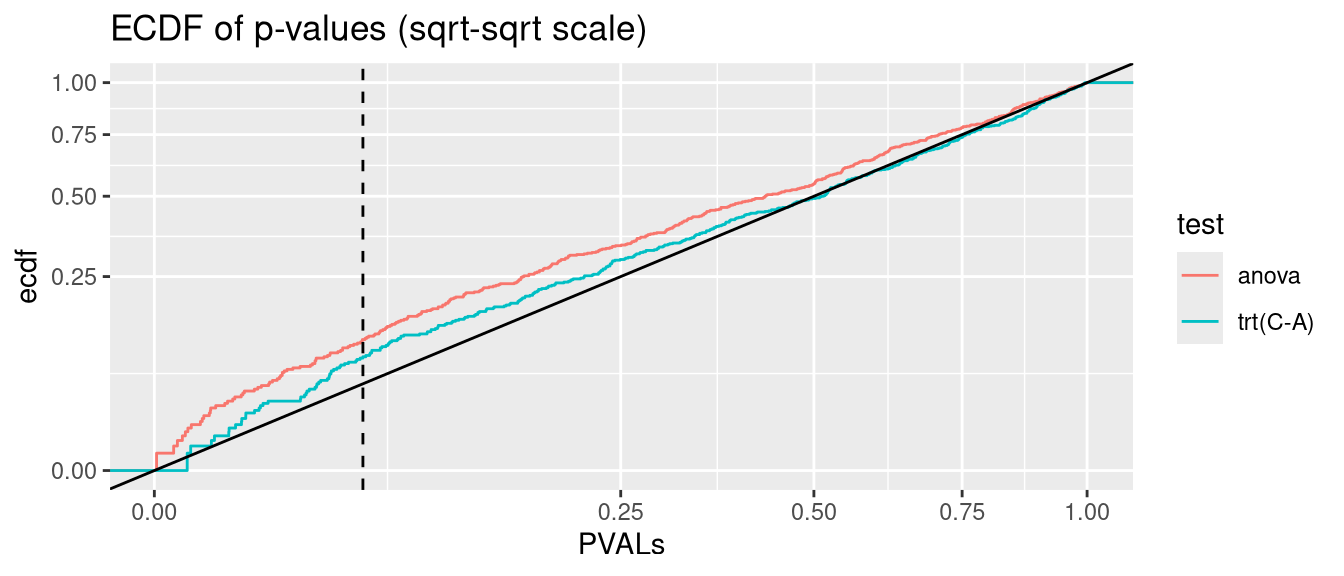
lmerTest::lmer has only slightly inflated Type I error rate. I suspect it is less powerful on heteroscedastic data though than nlme::lme.
Example:
glmmTMB(y ~ trt + (1|id), data = D, dispformula = ~trt)
nlme::lme(y ~ trt, random = ~1|id,
weights = varIdent(form = ~1|trt))
Note: Before modelling heteroscedastic LMM try:
fixing heteroscedasticity by transforming the response variable (log, sqrt, etc.)
Simplify mixed model structure by aggregating data like done in this post
R Functions
Data Simulation
Code
library(simr)library(glmmTMB) library(nlme)library(lmerTest)library(car)library(ggplot2)# Design MatrixX <-data.frame(id =as.factor(rep(1:40, each =10)),trt =as.factor(rep(c("A", "B", "C", "D"), each =100)))# Make it unbalancedset.seed(123)X <- X[-sample(101:300, 130, replace=FALSE),]# xtabs(~id+trt,X)# create NULL-lmer-modelmodel <-makeLmer(y ~ trt + (1|id), fixef=c(0,0,0,0),VarCorr =9,data = X, sigma =1 )# heteroscedastic responseget_hetero_data <-function(n) { D <- X D$y <-simulate(model, 1)[[1]] grpCD <- D$trt %in%c("C", "D") D$y[grpCD] <- D$y[grpCD] +rnorm(sum(grpCD), 0, 4)return(D)}# homoscedastic responseget_homo_data <-function(n) { D <- X D$y <-simulate(model, 1)[[1]]return(D)}
Analysis
analysis functions code
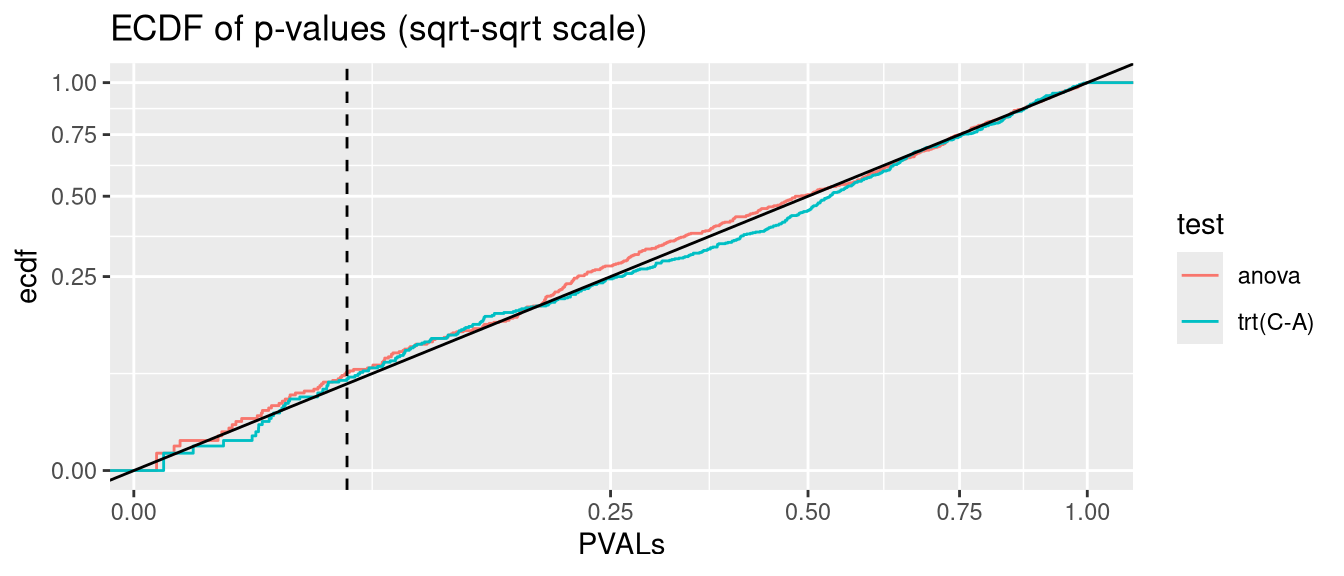
anova.glmmTMB <- glmmTMB:::Anova.glmmTMBanalysis <-function(nsim =500, data_fun = get_hetero_data, model_fun = glmmTMB, disp =FALSE){# seed <- 123 PVALs <- parallel::mclapply(1:nsim, \(seed){set.seed(seed) D <-data_fun()if(disp){if(identical(model_fun,nlme::lme)){ fit <-lme(y ~ trt, random =~1|id, data = D, weights =varIdent(form =~1|trt)) } else { fit <-model_fun(y ~ trt + (1|id), data = D, dispformula =~trt) } } else {if(identical(model_fun,nlme::lme)){ fit <-lme(y ~ trt, random =~1|id, data = D) } else { fit <-model_fun(y ~ trt + (1|id), data = D) } } A <-anova(fit) C <-if(identical(model_fun, glmmTMB)) coef(summary(fit))$cond elsecoef(summary(fit))c(anova=A["trt", ncol(A)], `trt(C-A)`=C["trtC", ncol(C)]) }) |>simplify2array()print(knitr::kable(as.data.frame(rbind(`fraction(PVALs < .05)`=rowMeans(PVALs <0.05),`binom.test(p = .05)`=apply(PVALs <0.05, 1, function(x) binom.test(sum(x), nsim, 0.05)$p.value) |>signif(2) )))) PVALS_long <- tidyr::pivot_longer(as.data.frame(t(PVALs)), cols =everything(), names_to ="test", values_to ="PVALs")ggplot(PVALS_long, aes(PVALs, group=test, col=test)) +stat_ecdf() +geom_abline(slope=1, intercept=0, col="black") +geom_vline(xintercept =0.05, col="black", linetype="dashed") +scale_x_sqrt() +scale_y_sqrt() +ggtitle("ECDF of p-values (sqrt-sqrt scale)")}