readRDS("cache/ResSum3.rds")| Covariate | FEELNAT | LNOISE |
|---|---|---|
| (Intercept) | 0.062 | -0.001 |
| LCARTIF_sqrt | -0.152** | -0.124* |
| LCARTIF_sqrt:RL_NDVI | 0.115** | |
| OVDIST_sqrt | 0.027 | |
| RL_NDVI | 0.150*** | |
| RL_NOISE | -0.242*** |
Lukas Graz 
For the release notes see the corresponding GitHub page
Data was split into training and test sets (50/50) for hypothesis testing to ensure valid inference after feature selection.
Missing value imputation was performed using MissForest doi:10.1093/bioinformatics/btr597. This method leverages conditional dependencies between variables to predict missing values through an iterative random forest approach.
To avoid introducing spurious correlations between different variable sets, we imputed the following data groups separately:
Mediators and GIS variables were intentionally not imputed on the test set to maintain valid inference, as MissForest does not provide a mechanism to propagate imputation uncertainty. An alternative would be the mice-routine, which could be implemented in future analyses. Missing values in the test set predictors remained untreated, which is justified under the missing completely at random (MCAR) assumption—where missing values occur independently of all other variables.
For the prediction analysis, fewer statistical assumptions are required, so using the MissForest approach does not violate any assumptions.
PRS variables could have been imputed separately for training/test sets and prediction analysis, but we prioritized simplicity as these variables serve only as response variables.
Additionally, we compared MissForest with simpler imputation methods (variable-wise and observation-wise mean imputation) for the PRS variables. Results confirmed that MissForest consistently outperformed these alternatives.
PCA Verification of this approach. Key findings:
Details and results in the notebook.
This section investigates predictive relationships between Perceived Restorativeness Scale (PRS) variables, mediator variables, and Geographical Information System (GIS) variables using various machine learning approaches. We employed a systematic methodology to quantify the predictive power of different variable combinations.
We evaluated multiple machine learning models using the mlr3 framework (cite doi:10.21105/joss.01903) :
Performance was measured as percentage of explained variance on hold-out data, calculated as (1 - MSE/Variance(y)), where MSE represents mean squared error.
To systematically explore predictive relationships, we tested four model configurations:
Details and results in the notebook.
Here we investigated which variables (including their interactions) influence PRS variables using multiple linear regression. With 190 variables (counting interactions), the variance inflation factor (VIF) was high and the multiple testing problem severe. We therefore implemented a stepwise feature selection using Bayesian Information Criterion (BIC) on the training data, starting with an empty model to help computational complexity. Selected features were subsequently used to fit models on the test set to obtain valid p-values. To keep the coefficients interpretable in the presence of interactions, each variable is scaled to mean 0 and standard deviation 1.
The analysis systematically explored two key relationship pathways:
For each target variable, we constructed a separate model using stepwise selection and evaluated it on the test dataset.
mice NA-handling likely unnecessary
Significant codes as usual: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
In [1]:
readRDS("cache/ResSum3.rds")| Covariate | FEELNAT | LNOISE |
|---|---|---|
| (Intercept) | 0.062 | -0.001 |
| LCARTIF_sqrt | -0.152** | -0.124* |
| LCARTIF_sqrt:RL_NDVI | 0.115** | |
| OVDIST_sqrt | 0.027 | |
| RL_NDVI | 0.150*** | |
| RL_NOISE | -0.242*** |
Significant codes as usual: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
In [2]:
readRDS("cache/ResSum4.rds")| Covariate | MEAN | FA | BA | EC | ES |
|---|---|---|---|---|---|
| (Intercept) | -0.005 | 0.006 | -0.008 | -0.006 | 0.027 |
| DISTKM_sqrt | -0.019 | 0.073. | |||
| FEELNAT | 0.252*** | 0.266*** | 0.252*** | 0.058 | 0.270*** |
| FEELNAT:LNOISE | 0.022 | -0.036 | |||
| LCFOREST_sqrt | -0.066. | -0.114** | |||
| LNOISE | 0.212*** | 0.170*** | 0.142** | ||
| LNOISE:FEELNAT | -0.013 | ||||
| RL_NDVI | -0.105** |
Details/Code and results in the notebook.
Procedure: Stepwise feature selection using BIC on training data and subsequent model fitting on test data. Performed seperately for RL_NDVI and RL_NOISE.
Predictors:: HM_NDVI + HM_NOISE + LANG + AGE + SEX + SPEED_log + JNYTIME_sqrt with all two-way interactions.
Visualizing the effect of HM_NOISE and JNYTIME_sqrt on RL_NOISE:
In [5]:
# Plot with matching color scales
ggplot() +
geom_raster(data = grid, aes(x = JNYTIME_sqrt, y = HM_NOISE, fill = predicted_RL_NOISE)) +
geom_jitter(data = D_tst, aes(x = JNYTIME_sqrt, y = HM_NOISE, col = RL_NOISE, shape = LANG),
width = 0.07, height = 0.1, alpha = 0.7) +
scale_fill_viridis_c(name = "Predicted\nRL_NOISE", limits = combined_range) +
scale_color_viridis_c(name = "Actual\nRL_NOISE", limits = combined_range) 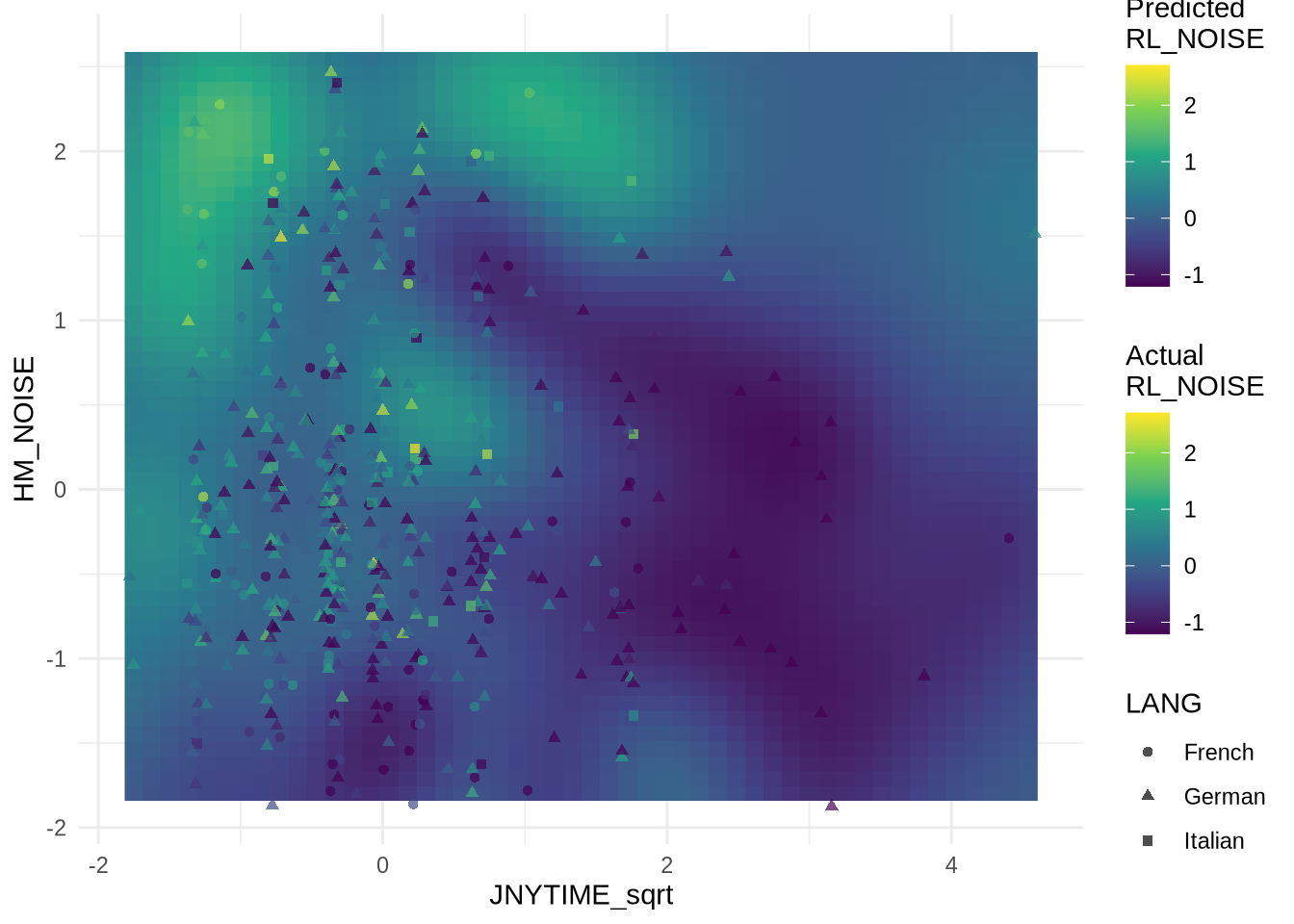
see the notebook.